Перевод http://www.codeproject.com/Articles/478485/Multi-Threaded-WebScraping-in-Csharp;
Парсинг сайтов — это получение интересующей информации с веб-страниц. Автор попытался сделать пошаговое руководство, начиная с основ парсинга с помощью компонента WebBrowser и заканчивая темами такими как выполнение логина и поддержания сессий через HTTPWebRequest.
Компонент WebBrowser
Этот контрол обеспечивает встроенный полноценный браузер в вашем приложении. Он позволяет пользователю перемещаться по веб-страницам внутри формы.
Пример: WebBrowser Download Event (событие загрузки)
- Добавьте контрол WebBrowser на форму. И выставите свойству Dock значение «Fill»
- Добавьте следующие события и код:
- Функция Navigate переходит по указанному адресу
- Событие DocumentCompleted возникает когда вэб страница загружена
- Запускайте программу
- Есть много способов решения вышеуказанной проблемы, например, подсчет фреймов на странице совместно с подсчетом количества срабатываний события DocumentCompleted. Это довольно таки сложно для начинающих, поэтому рассмотрим пример на основе ведения журналов.
- Добавьте List и модифицируйте наше событие загрузки страницы как показано ниже:
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
this.Text +=" a";
}
private void Form1_Load(object sender, EventArgs e)
{
webBrowser1.Navigate("http://jobtools.ru");
} 
List<string> hist = new List<string>();
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
if (hist.Contains(webBrowser1.Url.ToString()))
return;
this.Text +=" a";
hist.Add(webBrowser1.Url.ToString());
}
private void Form1_Load(object sender, EventArgs e)
{
webBrowser1.Navigate("http://jobtools.ru");
} Пример: Навигация по сайту
- Перед тем как создавать свой парсер сайтов, кликер-бота и т.п. необходимо разобраться с макетом документа, как искать и находить нужные блоки в документе
- Найдите на странице интересующий вас элемент
- Найдите id этого элемента на странице
- Для поиска id можно использовать FireFox, либо Chrome я использую последний
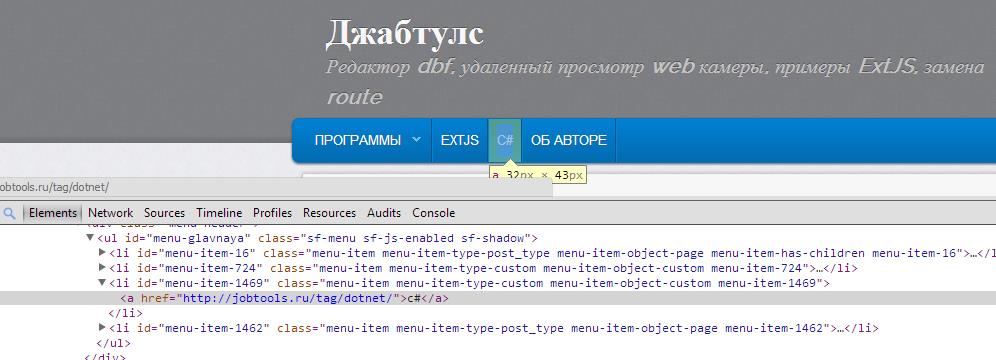
- Нажмите в Chrome F12 — Вы войдете в режим «Инструменты разработчика». Нажите на лупу и выберите интересующий вас элемент на странице
- Тег привязки (якорь), выделенные на картинке выше, не имеет никакого уникального идентификатора, поэтому, если мы используем функцию GetElementByTag(“a”), то мы получим список всех ссылок на странице, для нас это не вариант
- Итак, попробуем поискать ближайший элемент у которого есть ID. В нашем случае далеко ходить не надо это элемент li
- Теперь пишем код для выбора интересующей нас ссылки для этого находим li с id=menu-item-1469 и в нем уже ищем первую ссылку:
- Теперь мы можем получить адрес нашей ссылки:
<li id="menu-item-1469" class="menu-item menu-item-type-custom menu-item-object-custom menu-item-1469">
HtmlElement he = webBrowser1.Document.GetElementById("menu-item-1469");
HtmlElementCollection hec = he.GetElementsByTagName("a");
webBrowser1.Navigate(hec[0].GetAttribute("href")); Пример: Навигация по всем ссылкам на странице
- Для начала мы должны найти и сохранить все ссылки на странице, давайте не все ссылки а только те, что находятся в меню (id=menu-glavnaya). Для этого заведем список из строк, в который будем сохранять все значения атрибута href (сам адрес у ссылки):
- Модифицируем событие DocumentCompleted для сохранения всех ссылок:
- Теперь все ссылки сохранены в списке urls. Теперь код перехода по всем ссылкам:
List<string> urls = new List<string>();
HtmlElement he = webBrowser1.Document.GetElementById("menu-glavnaya");
HtmlElementCollection hec = he.GetElementsByTagName("a");
foreach (HtmlElement a in hec)
{
string href = a.GetAttribute("href");
if (href != "http://jobtools.ru")
{
if (!urls.Contains(href))
urls.Add(href);
}
} if(urls.Count > 0)
{
string u = urls[0];
urls.RemoveAt(0);
webBrowser1.Navigate(u);
this.Text = "Всего ссылок" + urls.Count.ToString();
}
else
{ MessageBox.Show("Завершено"); }
Пример: Заполняем и отправляем форму входа Yahoo
- Заходим на сайт http://mail.yahoo.com/;
- Находим ID формы ввода логина и пароля;
- Добавляем кнопку на форму и прописываем код в событии onClick
- Для отправки формы надо найти ID кнопки входа и вызвать функцию отправки формы следующим образом:
-
HtmlElement hf = webBrowser1.Document.GetElementById("login_form"); hf.InvokeMember("submit");
htmlElement hu = webBrowser1.Document.GetElementById("username");
hu.Focus();
hu.SetAttribute("Value","userName");
HtmlElement hp = webBrowser1.Document.GetElementById("passwd");
hp.Focus();
hp.SetAttribute("Value", "password"); Пример: Установка значений для Referrer и User-Agent
webBrowser1.Navigate("url", "_blank", null, "Referrer: sample user agent"); Пример: Сохранить все изображения на странице
- Добавьте ссылку using mshtml;
- И используем следующий код, который сохраняет все картинки в папку с программой
IHTMLDocument2 doc = (IHTMLDocument2)webBrowser1.Document.DomDocument;
IHTMLControlRange imgRange = (IHTMLControlRange)((HTMLBody)doc.body).createControlRange();
foreach (IHTMLImgElement img in doc.images) {
imgRange.add((IHTMLControlElement)img);
imgRange.execCommand("Copy", false, null);
try{
using(Bitmap bmp = (Bitmap)Clipboard.GetDataObject().GetData(DataFormats.Bitmap))
bmp.Save(img.nameProp + ".jpg");
}
catch (System.Exception ex)
{
MessageBox.Show(ex.Message);
}
} Пример: Разбор капчи используя API DeathByCaptcha
- Подключаем ссылку using DeathByCaptcha;
- Используем следующий код (тут всё просто)
Client client = (Client)new SocketClient(capUser, capPwd);
try
{
Captcha captcha = client.Decode(path + capName, 50);
if (null != captcha)
{
//Captcha Solved
MessageBox.Show(captcha.Text);
}
else
{
//Captcha Not Solved Show Error Message
}
}
catch(DeathByCaptcha.Exception ex) {
MessageBox.Show(ex.Message);
} Пример: Как задать Proxy для WebServer
using Microsoft.Win32;
RegistryKey reg = Registry.CurrentUser.OpenSubKey(
"Software\\Microsoft\\Windows\\CurrentVersion\\InternetSettings", true);
registry.SetValue("ProxyEnable", 1);
registry.SetValue("ProxyServer", "192.168.1.1:9876");
Отличная статья, спасибо пригодилась
Спасибо! Надо добраться до продолжения!
Спасибо за статью, пригодилась. Но Вы писали, что можно организовать «…подсчет фреймов на странице совместно с подсчетом количества срабатываний события DocumentCompleted…». Можете описать каким образом это реализовать. Спасибо.
А можете показать пример как парсить статистику сервера с сайта мониторинга по типу Статус Онлайн или в Оффлайн и количество игроков?
Если эта информация выводится на сайте, то это легко, дайте адрес сайта для примера.
Помню в WoW статистику отдавал специальный скрипт на php что ли. Вообщем дайте адрес сайта, а там попробуем
gs4u. net/dayzm/217.23.139.34:2302. html пробелы надо убрать
Нужна строчка Статус:Онлайн и строчка играков: 0 из 2
//Загружаем страничцу
webBrowser1.Navigate(«http://gs4u.net/dayzm/217.23.139.34:2302.html»);
//после загрузки страницы в DocumentCompleted парсим
HtmlElementCollection he = webBrowser1.Document.GetElementsByTagName(«td»);
Label1.Text = he[25].InnerText;
выбрали все элементы td на странице, так как в вашем случае id не прописан.
25 элемент td как раз и содержит необходимую Вам информацию.
Я перешел на использование php для парсинга страниц, и по сравнению с ним этот вариант в статье очень уж не удобен и ограничен.
Быстрее, функциональней делать так как описано в этом примере
используя описанные там библиотеки