В последнее время начал интересоваться SEO для продвижения своих сайтов, что такое семантическое ядро, позиции в выдаче гугла или яндекса. В связи с чем начал периодически проверять позиции своих своих сайтов в поисковых системах, и практически все программы и сервисы для проверки оказались либо платными, либо с урезанным функционалом.
Решил попробовать, а заодно и узнать, как сложно это в реализации. Оказалось всё очень просто, если бы не пара мелочей, которые съели два часа моего времени впустую.
Итак что получилось:
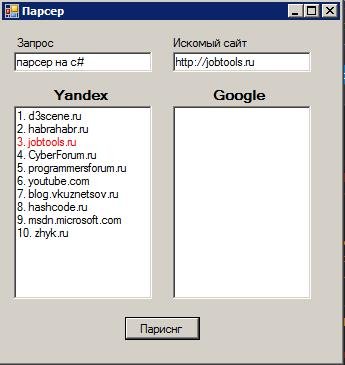
- Парсинг выдачи ТОП-10 yandex по ключевому запросу;
- Форма ввода капчи (вот с этим пунктом и провозился)
- Определение позиции искомого сайта;
Для написания программки были использованы две сторонние бесплатные утилиты:
- XNet -содержит все необходимые классы для работы по HTTP и многое другое
- HTMLAgilityPack — удобный парсинг HTML документов
Основной код программы
//Очистили список сайтов
rtbYandex.Clear();
//Страница поиска - 0 это первая страница в яндексе
int page = 0;
//непосредственно сам запрос
string zapros = @"http://yandex.ru/yandsearch?text=" +HttpHelper.UrlEncode(tbZapros.Text) + "&p=" + page + "&rnd=28759";
string content = "";
string key_captcha = "";
string return_path_captcha = "";
string url_captcha = "";
var request = new HttpRequest();
//Установили куки
CookieDictionary cookie = new CookieDictionary();
request.Cookies = cookie;
request.UserAgent = HttpHelper.FirefoxUserAgent();
// Отправляем запрос.
request.Referer = HttpHelper.UrlEncode(zapros);
HttpResponse response = request.Get(zapros);
// Принимаем тело сообщения в виде строки.
content = response.ToString();
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
HtmlNodeCollection nodes;
doc.LoadHtml(content);
//Парсим страницу на наличие капчи
nodes = doc.DocumentNode.SelectNodes("//div[@class='b-captcha']");
//И если капча есть переходим к её обработке
if (nodes != null)
{
HtmlNodeCollection inputs = nodes[0].SelectNodes("//input");
key_captcha = inputs[0].GetAttributeValue("value", "false").Replace("&amp", "");
return_path_captcha = inputs[1].GetAttributeValue("value", "false").Replace("&", "&"); ;
//Парсим страницу на получение тэга <img>, в котором прописана капча
HtmlNode image = doc.DocumentNode.SelectSingleNode("//td[@class='b-captcha__layout__l']//img");
//Получаем URL капчи (путь по которому её можно скачать)
url_captcha = image.GetAttributeValue("src", "true");
//Скачиваем картинку с удаленного адреса в MemoryStream
MemoryStream stream = request.Get(url_captcha).ToMemoryStream();
//Создаем форму ввода капчи
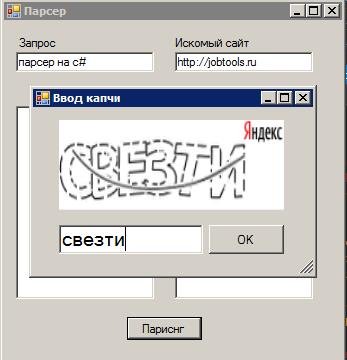
FormCaptcha formCaptcha = new FormCaptcha();
//Отображаем в PictureBox картинку с MemoryStream
formCaptcha.pictureBox1.Image = Image.FromStream(stream);
//Отображаем форму ввода капчи для пользователя
formCaptcha.ShowDialog();
request.AddUrlParam("key", HttpHelper.UrlEncode(key_captcha));
request.AddUrlParam("retpath", HttpHelper.UrlEncode(return_path_captcha));
request.AddUrlParam("rep", HttpHelper.UrlEncode(formCaptcha.tbPassword.Text));
//request.AddHeader("Host","yandex.ru");
response = request.Get(@"http://yandex.ru/checkcaptcha");
doc.LoadHtml(response.ToString());
}
//Парсим страницу на блоки со ссылками
nodes = doc.DocumentNode.SelectNodes("//div[@class='serp-list']//span[@class='serp-url__item']//a[1]");
int count = 0;
int pos = 0;
if (nodes == null)
return;
foreach (HtmlNode node in nodes)
{
count++;
rtbYandex.AppendText(count + ". " + node.InnerText + "\n");
if ("http://".ToUpper()+ node.InnerText.ToUpper() == tbSite.Text.ToUpper())
{
rtbYandex.Select(pos, node.InnerText.Length+3);
rtbYandex.SelectionColor = Color.Red;
}
pos += node.InnerText.Length + 1 + (Convert.ToString(count) + ". ").Length;
}
Старался в комментариях подробно всё расписать.
Особой запаркой для меня стала отправка капчи на сайт Яндекса, он всегда отвечал ошибкой, что такая страница не найдена. Вооружившись триальной программой Http Sniffer проанализировал трафик ввода капчи с сайта яндекса и после её ввода в своей программе:
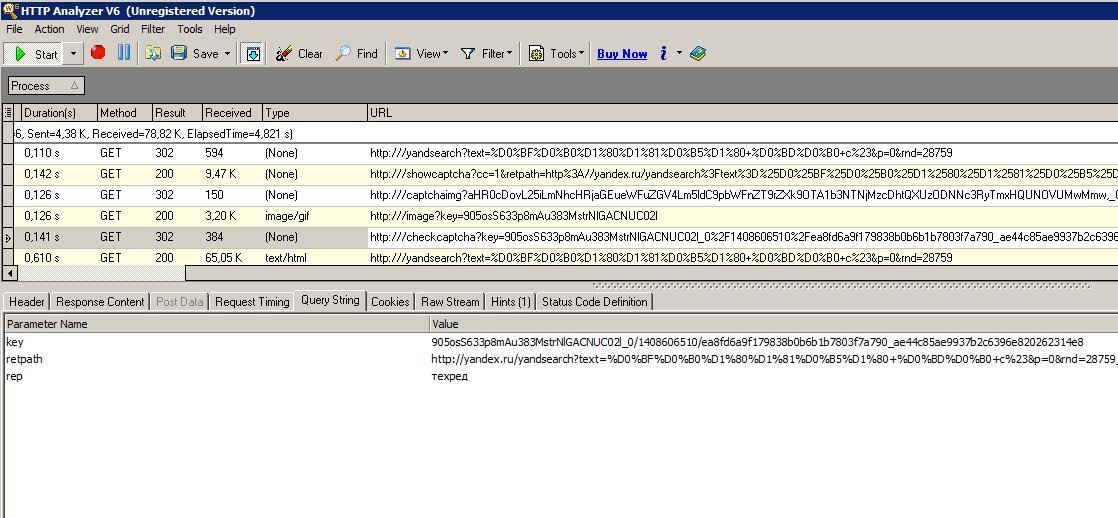
Обнаружилось (так и не понял почему, да и не стал дальше разбираться), что в моих запросах к серверу фигурировало следующее слово «&» — удалив его из строки запроса всё стало работать, как надо.
Еще пара нюансов:
Обязательно надо использовать куки, это делают следующие строчки:
CookieDictionary cookie = new CookieDictionary(); request.Cookies = cookie;
Так как yandex присваивает каждому запросу уникальный параметр spravka
Обязательно использование HttpHelper.UrlEncode — кодирует строку для передачи её по протоколу HTTP
Ответ на капчу формируется с тремя параметрами:
retkey — это адрес куда произойдет перенаправление, если капча введена правильно
key — уникальный идентификатор изображения
rep — значение самой капчи
Оказалось все очень просто. Планирую реализовать парсинг Google, использование antigate, а там уже можно делать и универсальную программу с банальными, но бесплатными функциями и назвать это SEOShow 8)
Сорцы бы залил.
Если бы выложил исходники — был бы бесценный материал!!!
Выложил. Теперь можно скачать исходники парсера Yandex.
Я подзабил на это дело. Дальше описанного в статье дело не пошло
зря. Мне, как начинающему программисту, было интересно.
У кого работает? Сервер выдаёт ошибку 400 при отправке строки!